
Isolation Level(격리 수준)
여러 트랜잭션이 수행되었을 때 알아두어야할 Isolation level


데이터베이스 격리 수준은 여러 트랜잭션이 동시에 수행될 때 데이터베이스의 일관성과 정확성을 보장하기 위해 설정하는 규칙이다. 이는 트랜잭션이 서로의 작업에 영향을 미치는 방식을 제어하여, 데이터 무결성을 유지하고 데이터 손상이나 충돌을 방지한다. 대표적인 데이터베이스 격리 수준에는 읽기 불가능(Dirty Read), 비반복 읽기(Non-repeatable Read), 팬텀 읽기(Phantom Read)와 같은 문제가 있다. 이러한 문제를 해결하기 위해 ANSI/ISO SQL 표준에서는 다음과 같이 네 가지 격리 수준을 정의했다.
Read Uncommitted
Read Committed
Repeatable Read
Serializable
Read Uncommitted는 가장 낮은 수준의 격리 수준으로, 한 트랜잭션이 커밋되지 않은 데이터를 다른 트랜잭션이 읽을 수 있게 한다. 이는 데이터 일관성을 거의 보장하지 않으며, Dirty Read 문제가 발생할 수 있다. 예를 들어, 트랜잭션 A가 데이터를 수정하고 아직 커밋하지 않은 상태에서 트랜잭션 B가 이 데이터를 읽는 경우, 트랜잭션 A가 롤백되면 트랜잭션 B는 유효하지 않은 데이터를 읽은 것이 된다. 이로 인해 데이터의 신뢰성이 낮아질 수 있다.
Read Committed는 한 트랜잭션이 커밋된 데이터만 읽을 수 있도록 하는 격리 수준이다. 이는 Dirty Read 문제를 방지하지만, 비반복 읽기 문제가 발생할 수 있다. 예를 들어, 트랜잭션 A가 데이터를 읽고, 이후 트랜잭션 B가 그 데이터를 수정하여 커밋한 후 트랜잭션 A가 동일한 데이터를 다시 읽으면 다른 값을 얻게 된다. 이러한 상황은 데이터의 일관성을 해칠 수 있다.
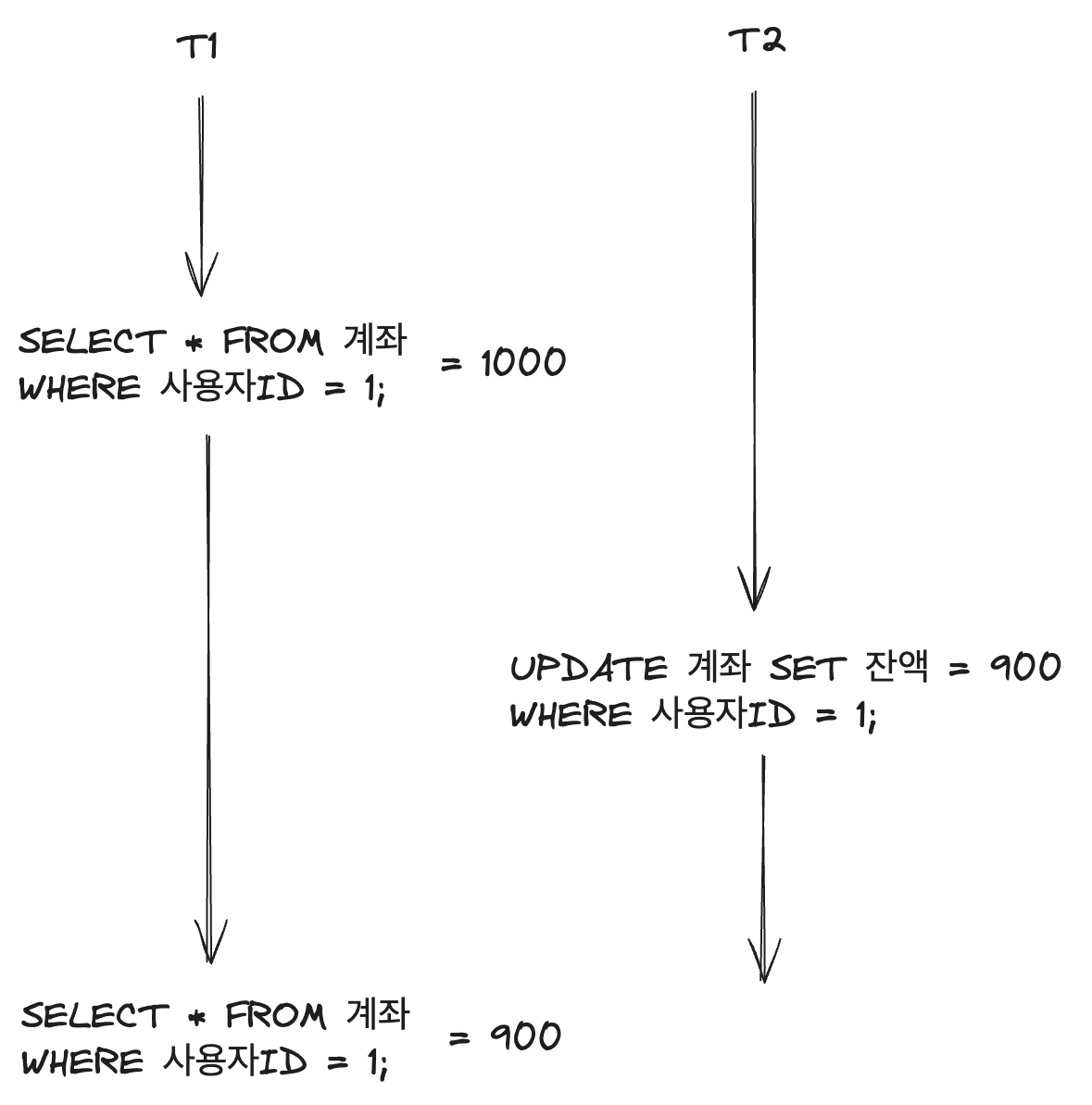
Repeatable Read는 트랜잭션이 시작된 후 다른 트랜잭션이 데이터를 수정할 수 없도록 하는 격리 수준이다. 이는 Dirty Read와 비반복 읽기 문제를 방지하지만, 팬텀 읽기 문제는 여전히 발생할 수 있다.(일부만 발생하고, 대부분의 엔진에서는 보호해준다!) 예를 들어, 트랜잭션 A가 특정 조건에 맞는 데이터 집합을 읽고, 이후 트랜잭션 B가 새로운 데이터를 삽입한 후 커밋하면, 트랜잭션 A가 동일한 조건으로 다시 데이터를 읽을 때 새로운 데이터가 포함될 수 있다. 이러한 상황은 데이터의 일관성을 해칠 수 있다.

Serializable는 가장 높은 수준의 격리 수준으로, 모든 트랜잭션이 순차적으로 실행되는 것처럼 보이게 한다. 이는 Dirty Read, 비반복 읽기, 팬텀 읽기 문제를 모두 방지한다. 하지만, 높은 수준의 동시성 제어가 필요하기 때문에 성능에 영향을 줄 수 있다. 예를 들어, 트랜잭션 A와 트랜잭션 B가 동시에 실행될 때, 한 트랜잭션이 완료될 때까지 다른 트랜잭션이 대기해야 한다. 이는 데이터의 일관성을 보장하지만, 시스템의 처리 성능을 저하시킬 수 있다.
각 격리 수준은 특정 상황에서의 데이터 일관성과 성능 요구 사항에 따라 선택된다. Read Uncommitted는 성능이 중요한 시스템에서 사용될 수 있지만, 데이터 정확성이 중요한 경우에는 사용되지 않는다. Read Committed는 대부분의 애플리케이션에서 적절한 성능과 데이터 일관성을 제공한다. Repeatable Read는 더 높은 수준의 데이터 일관성을 요구하는 경우에 적합하며, Serializable은 데이터의 정확성과 일관성이 최우선인 경우에 사용된다.
데이터베이스 격리 수준을 이해하고 적절히 설정하는 것은 안정적이고 신뢰할 수 있는 데이터베이스 시스템을 구축하는 데 매우 중요하다. 이는 트랜잭션 처리 중 발생할 수 있는 다양한 문제를 예방하고, 데이터 무결성을 유지하는 데 도움을 준다. 따라서, 개발자와 데이터베이스 관리자 모두 데이터베이스 격리 수준에 대한 깊은 이해가 필요하다.