
RDB 동기 복제(Synchronous Replication)
RDB의 일반적은 복제 방식에 대해 알아보자.


관계형 데이터베이스(RDB)는 데이터의 구조와 무결성을 보장하며, 데이터베이스 관리 시스템(DBMS)을 통해 데이터를 효율적으로 관리한다. 이러한 데이터베이스 시스템에서 데이터의 가용성과 안정성을 높이기 위한 방법 중 하나로 동기 복제가 있다. 동기 복제는 주 서버와 복제 서버 간의 데이터 일관성을 실시간으로 유지하여, 데이터 손실을 최소화하고 시스템의 신뢰성을 높이는 기술이다.
동기 복제는 주 서버에서 트랜잭션이 발생할 때마다 복제 서버에 동일한 트랜잭션이 즉시 적용되도록 보장한다. 이는 트랜잭션이 주 서버에서 커밋될 때, 해당 트랜잭션이 복제 서버에서도 성공적으로 커밋될 때까지 기다리는 방식으로 구현된다. 이를 통해 데이터 일관성을 확보할 수 있다. 예를 들어, 은행 시스템에서 계좌 이체가 발생할 경우, 동기 복제는 주 서버와 복제 서버 모두에 이체 정보가 정확히 반영되도록 하여 데이터 불일치를 방지한다.
동기 복제의 주요 이점 중 하나는 데이터 손실 가능성을 크게 줄일 수 있다는 점이다. 주 서버가 장애로 인해 중단되더라도, 복제 서버가 즉시 주 서버 역할을 대체할 수 있어 시스템 다운타임을 최소화할 수 있다. 이는 고가용성이 요구되는 시스템에서 매우 중요한 요소이다. 또한, 동기 복제는 데이터베이스 백업과는 달리 실시간으로 데이터 복제를 수행하기 때문에, 최신 데이터가 항상 복제 서버에 존재하게 된다.
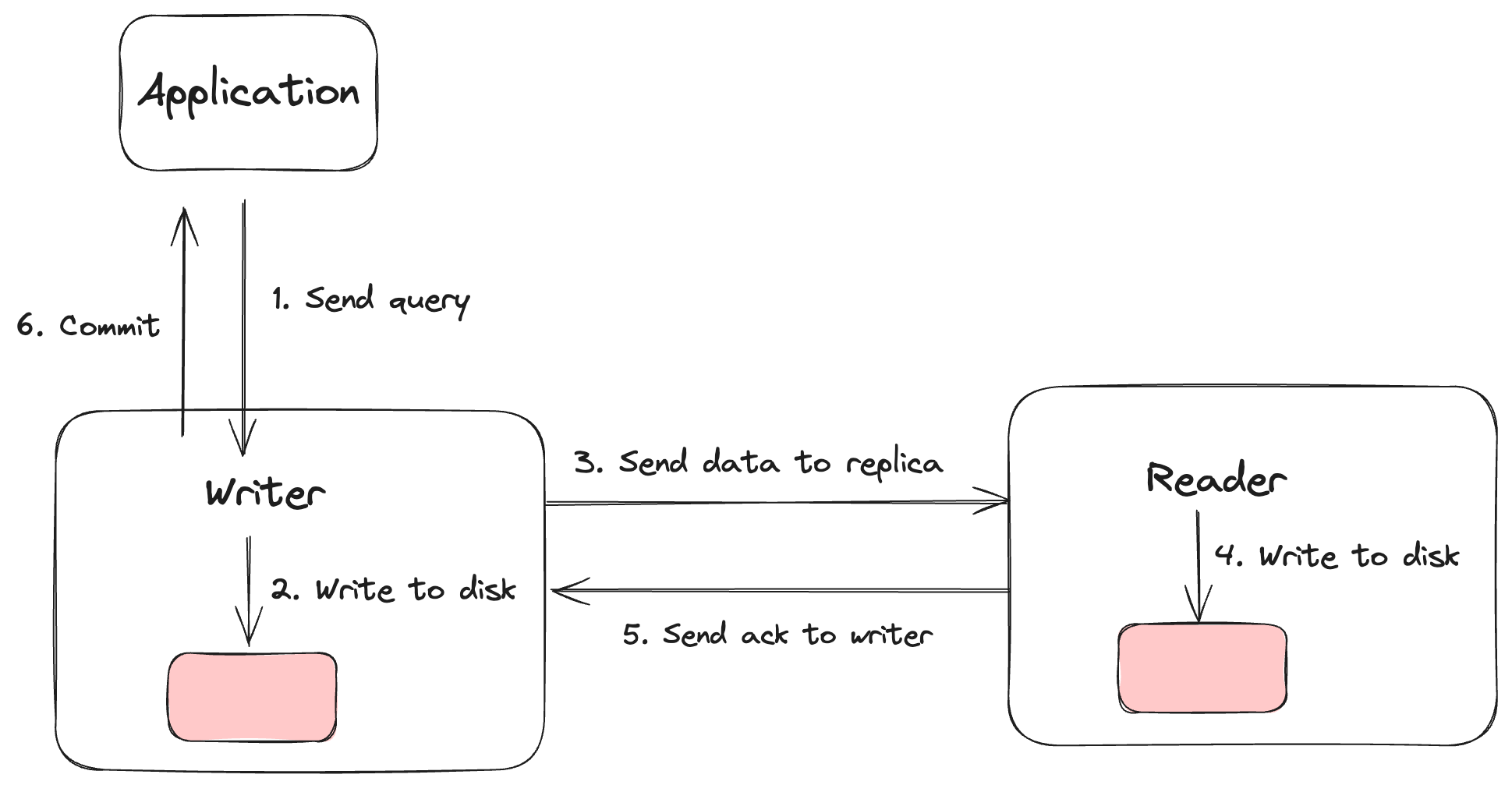
그러나 동기 복제는 몇 가지 단점도 가지고 있다. 가장 큰 문제는 성능 저하이다. 주 서버가 트랜잭션을 커밋할 때마다 복제 서버의 응답을 기다려야 하기 때문에, 전체 시스템의 처리 속도가 느려질 수 있다. 이는 특히 고성능이 요구되는 시스템에서는 중요한 문제로 작용할 수 있다. 따라서 동기 복제를 도입할 때는 시스템의 성능 요구 사항을 면밀히 검토하고, 적절한 하드웨어와 네트워크 인프라를 갖추는 것이 중요하다.
또한, 동기 복제는 네트워크 대역폭을 많이 소모할 수 있다. 주 서버와 복제 서버 간의 데이터 전송이 빈번하게 발생하기 때문에, 네트워크 성능이 중요한 역할을 한다. 네트워크 지연이나 대역폭 제한이 있는 환경에서는 동기 복제가 원활하게 작동하지 않을 수 있다. 따라서, 동기 복제를 효율적으로 운영하기 위해서는 고속 네트워크 인프라가 필수적이다.
동기 복제의 구현 방법에는 여러 가지가 있다. 가장 일반적인 방법은 데이터베이스 관리 시스템(DBMS)의 내장 기능을 사용하는 것이다. 많은 상용 및 오픈 소스 DBMS는 동기 복제 기능을 제공하며, 이를 통해 비교적 간단하게 동기 복제를 설정할 수 있다. 예를 들어, MySQL의 InnoDB Cluster, PostgreSQL의 Streaming Replication 등이 대표적인 예이다. 이러한 기능을 활용하면, 별도의 복잡한 설정 없이도 신뢰성 높은 동기 복제를 구현할 수 있다.
또한, 동기 복제를 구현할 때는 데이터베이스의 트랜잭션 일관성을 유지하기 위한 여러 가지 기법이 사용된다. 그 중 하나는 2단계 커밋(two-phase commit)이다. 2단계 커밋은 트랜잭션이 커밋되기 전에 주 서버와 복제 서버가 모두 준비되었는지 확인하는 과정을 거친다. 이를 통해 주 서버와 복제 서버 간의 데이터 불일치를 방지할 수 있다.
다른 기법으로는 WAL(Write-Ahead Logging)을 이용한 복제가 있다. WAL은 트랜잭션 로그를 먼저 기록하고, 이를 기반으로 복제 서버에 적용하는 방식으로, 데이터 일관성을 유지하면서도 성능을 어느 정도 확보할 수 있다.
결론적으로, 동기 복제는 데이터베이스 시스템의 신뢰성과 가용성을 높이는 중요한 기술이다. 데이터 일관성을 실시간으로 유지함으로써 데이터 손실을 최소화하고, 장애 상황에서도 신속하게 시스템을 복구할 수 있다. 그러나 성능 저하와 네트워크 대역폭 소모 등의 문제를 해결하기 위해서는 적절한 시스템 설계와 인프라 구축이 필수적이다. 다양한 DBMS가 제공하는 동기 복제 기능을 활용하여, 효율적이고 안정적인 데이터베이스 시스템을 구현하는 것이 중요하다.